Extracting Your Content from Wordpress with Python
I've had a simple blog on WordPress since 2011. Over the years, the account has been hacked several times and it has been a general nightmare. It is also a free account, (because who pays for WordPress?) and it is littered with ads. Ads that are making someone else money on my content. I have basically ignored it for the last five years, but something has come up that has made me readdress it.
The DoD filtering system has deemed my site to have “insufficient content”, which means my site is filtered on any DoD computer system. I can't find a description for what criteria are used to determine this from the DoD, but Google Ad Sense says roughly ~50 pages are good enough for them. So I need to add more content (pages) to my site. While I have a multitude of projects sitting on my hard drive that need to be documented, I just needed something fast.
Hence, why I needed to strip the content from my old, dormant blog about pilot training and host it here. I didn't need any of the services provided by WordPress, so I could strip everything but the post's title, creation date, text content, and images. If you go over to the dashboard for your WordPress site, you will find a dropdown in the menu called “export”:
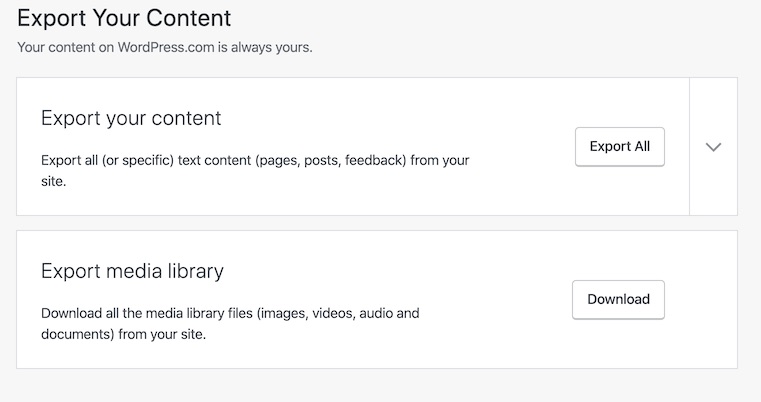
If you click on export all, you'll get a single file in XML format that has all the content you need. Second, the export media button will download all of your media with the same folder structure as it's referenced as on your site.
Python and XML
I've never really worked with XML, but it's pretty easy to grok. It's basically HTML with custom tags.
After some googling, I came up with the code below. Here's a rough overview of what the code is doing:
|
|
Import the important stuff needed for working with XML and some string functions.
|
|
Parse the XML file from WordPress into a DOM object and convert it to a document element.
|
|
All of the posts and images are stored under “item” tags, so get a collection of them!
|
|
Here's where the magic happens:
- For every item, check to see if it is a post.
- If it is, let's spit out a file with the front matter needed for Hugo to create the post from markdown
- Write the content of the post to file
- Every picture on the site is tagged as a wp:attachment. The attachments have parent posts, which are integer numbers.
- Loop through all the attachment posts, check if the attachment's parent matches the current post.
- If so, write to file the markdown needed to display with hugo. (Note, I took out the url line 11 because I don't want to give them any link backs on accident, but it was the full base url to my WordPress site).